Why TM1py changed everything!
Just recently there was this interesting discussion about TurboIntegrator vs TM1py here on GitHub. That inspired me to share my personal view on ‘why TM1py changed everything for the TM1 ecosystem’.
Never has an outside product had a bigger impact on our functional database. It created a whole new subspecies of TM1 enthusiasts around the globe. If you do not believe me, check on LinkedIn how many people identify as TM1py developers. And the number is increasing every day! So let me explain how I think that happened.
The Old Ways
Remember the quick and dirty way to get data out of your TM1 system? Just click right on a cube and choose ‘Export as Text Data’. There you can either select a view or create a new one on the fly. You end up with a rather decent text file that you can use in other tools (like Tableau or PowerBI) or for further analysis via R or Python.
Unfortunately that is a manual process and you have to handle the flat file with all its possible problems. (Did someone say encoding?) And of course the security concept must allow for the possibility and you must have access to either Perspectives or Architect.
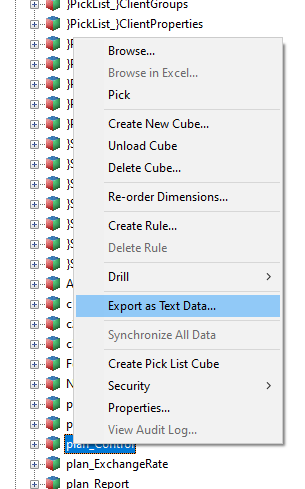
Manual Export via Architect
If you are lucky, you have not only access to one of those tools but are also an admin user. Then you can create your own TurboIntegrator process which exports a subsection of the cube via ASCIIOutput into a text file. Hopefully it does not mix up the decimal separator and the column delimiter is not used in an element name. But otherwise you will be fine and the best part is: You can schedule it. But you still end up with a text file.
If you are not an admin, you could still rely on that but always need an admin to change your export settings. That gets especially annoying when you change something in your analysis code and then have to match that change with the export and have to wait on someone to change it.
The New Way
In comes TM1py! Suddenly every user with access to a TM1 database could now retrieve data from that database without the need for an admin or an installation of certain tools (expect maybe Python :-) ). Three lines of code and you have your cube data in a Pandas DataFrame and with it all the possibilities of Pythons ‘batteries included’. Those three lines is all a data analyst needs to know about the inner workings of TM1.
from TM1py import TM1Service
with TM1Service(address='localhost', port=12354, ssl=True, user='admin', password='apple') as tm1:
df = tm1.cubes.cells.execute_view_dataframe(cube_name='plan_BudgetPlan', view_name='Default')
From here on out everything is Python and Pandas or any other Python package you can think of. When TM1py arrived, it had no real impact on the big world of Python. But in the small corner of functional databases, namely TM1, it changed everything. Suddenly everyone was able to easily export data from TM1.
With your TM1 data in a DataFrame, you can do Forecasting, Data Mining, Machine Learning, etc. - all with the data from your good, old functional database. But TM1py makes even TM1-related tasks easier. Think about comparing data between two cubes in the same instance or even between instances. Pandas has a function for that.
df.compare(df2)
So now you know why I think TM1py changed everything. How did I come to that conclusion? Because it is happening at my company. At Deutsche Bahn we have hundreds of TM1 databases and those are used in many different ways. There are many people who just need some information from the database and are not actively using any of the many frontends we provide. For them TM1py offers an easy way to work with the data without too much overhead. All thanks to TM1py!
Written by  Christoph Hein
Christoph Hein